Abschlussarbeiten
Bachelor- und Masterarbeiten werden aus verschiedenen Forschungsbereichen des Lehrstuhls angeboten. Hierbei werden konkrete Themen in der Regel vom Lehrstuhl angeboten (s.u.) oder in Zusammenarbeit mit der/dem Studierenden definiert.
Um eine Abschlussarbeit am Lehrstuhl für Erkl?rbares Maschinelles Lernen zu schreiben, gelten in der Regel folgende Voraussetzungen:
- erfolgreiche Prüfung in einem Modul mit Vorlesung und ?bung in DeepLearning (für Masterarbeit), Maschinelles Lernen oder Einführung in die KI
- erfolgreiche Teilnahme an einem vom Lehrstuhl angebotenen Seminar oder Projekt
Offene Abschlussarbeiten
Please refer to VC [Link] for further details.
Laufende Abschlussarbeiten
- “Evaluating and Enhancing Data Privacy in Distributed Environments with Non-Parametric Federated Learning using Pre-Trained Foundation Models” - Hanh Huyen My Nguyen, betreut von Francesco Di Salvo
- “Developing a comprehensive dataset and baseline model for classification and generalizability testing of gastric whole slide images in computational pathology” - Dominic Harold Liebel, betreut von Christian Ledig
- “Evaluating Hyperspherical Embeddings and Targeted Augmentations for Generalizable Medical Image Analysis" - Muhammad Tayyab Sheikh, betreut von Francesco Di Salvo
- “Analyzing the Correlation Between Performance and Representational Capability in Foundation Models through CLS Token Inversion and Key Self-Similarity” - Maximilian Jan Grudka, betreut von Sebastian D?rrich
- "Design and Implementation of an Unreal Engine 5 Plugin for Generating Photorealistic and Semantically Controllable Synthetic Data to Evaluate the Robustness of ImageNet Classifier" - Florian Gutbier, betreut von Sebastian D?rrich
- “Exploring Methods to Assess Scanner-Induced Domain Shifts in Medical Imaging” - Kian Fried Hinke, betreut von Sebastian D?rrich
- “Developing a Task-Agnostic Data Augmentation Method via Foreground Extraction, Object Relocation, and Generative Inpainting” - Roza Gaisina, betreut von Sebastian D?rrich
- Johannes Leick, betreut von Jonas Alle
Abgeschlossene Abschlussarbeiten
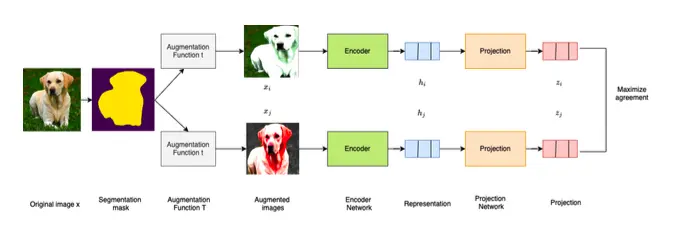
?Exploring Self-Supervise Learning Through SimCLR: Reproducing and Evaluating Natural Image Classification and Transfer Learning Accuracy” - Sascha Wolf
Autor: Sascha Wolf, betreut von Jonas Alle
This thesis explores enhancements to the SimCLR framework, a prominent method in self-supervised contrastive learning. The core contribution is SegAug-SimCLR, a segmentation-based augmentation pipeline that leverages semantic image segmentation to apply targeted data augmentations. Using DeepLabV3, images are split into foreground and background, enabling region-specific transformations. This method preserves object details while increasing training data variability. Experiments on ImageNet (pretrained on 10% training data) show a modest Top-1 accuracy improvement of 0.6%. Transfer learning on datasets like Oxford Flowers yields taskdependent gains (+1.0%). However, the eVects of segmentation-based augmentations on full ImageNet pretraining remain an open area for future research.
Link to thesis(2.7 MB)
Link to code

?Large Language Model-driven Sentiment Analysis for Exploring the Influence of Social Media and Financial News on Stock Market Development” - Pascal Cezanne
Autor: Pascal Cezanne, betreut von Sebastian D?rrich
This thesis explores the challenge of predicting stock price movements based on financial news, addressing the gap between textual sentiment and actual market reactions. Traditional sentiment analysis fails in this context, as positive or negative sentiment does not directly translate to bullish or bearish market movements. To tackle this issue, a dataset was created, linking financial news titles to historical price data using Rate of Return and Excess Return as target variables. This approach isolates external market factors, enabling market sentiment predictions.
To counteract the inherent class imbalance in financial datasets, various textual data augmentation techniques were evaluated, including advanced LLM-assisted methods. These techniques proved essential in mitigating overfitting, ensuring model robustness. The research further demonstrated that pre-trained sentiment models like FinBERT are ineffective for market predictions, necessitating training with price-based target data.
Experimental results showed that the developed model performs comparably to other machine learning-assisted trading strategies. While challenges remain in fully capturing the complexities of financial markets, this work provides with its dataset a foundation for future research into stock-aware sentiment analysis and market prediction models.
However, the thesis does not delve into training a model that explicitly makes stock-aware predictions, making this a subject for future research.
Link to thesis(8.8 MB)
Link to code
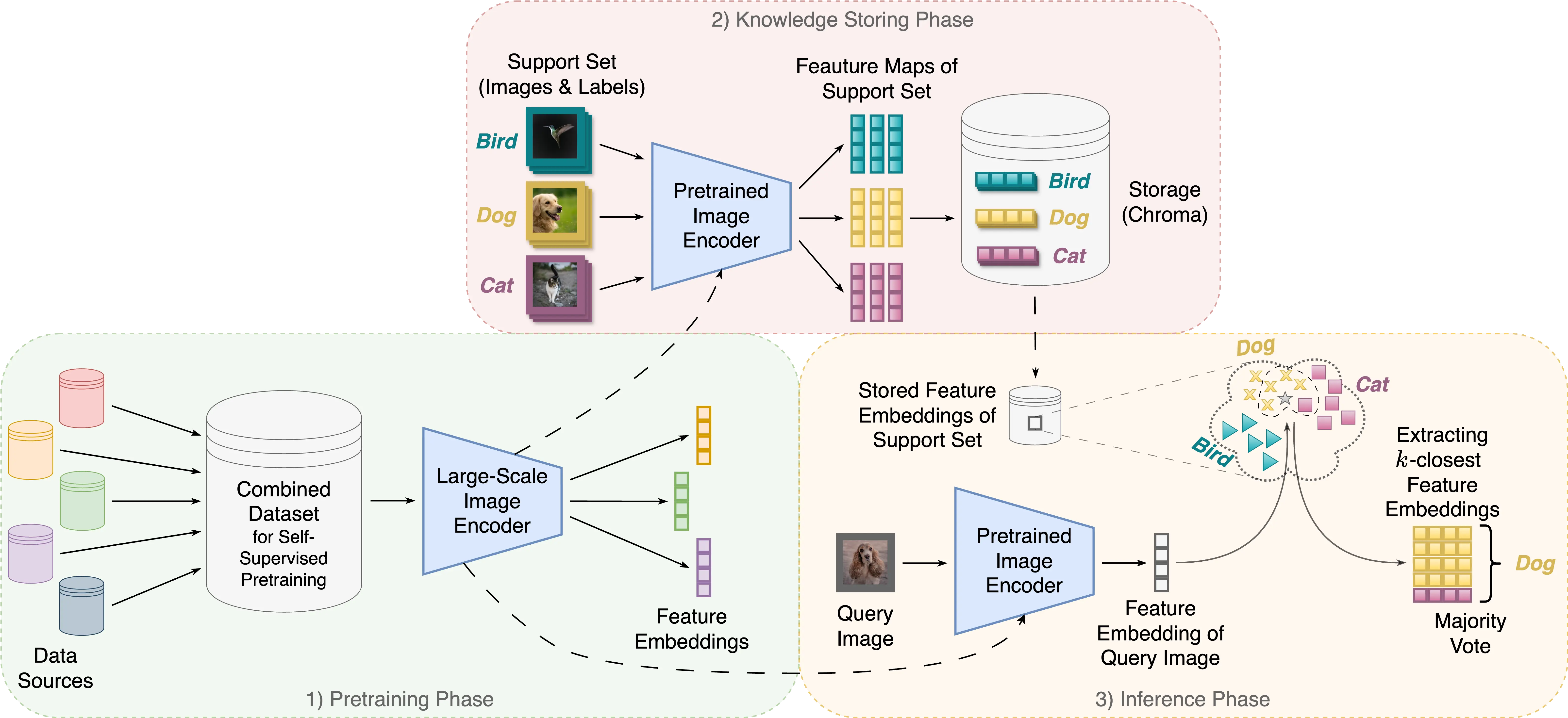
?Addressing Continual Learning and Data Privacy Challenges with an explainable kNN-based Image Classifier” - Tobias Archut
Autor: Tobias Archut, betreut von Sebastian D?rrich
This thesis explores the challenge of continual learning and data privacy in image classification and presents an explainable k-NN-based approach as a solution. Traditional deep learning models struggle with adapting to new data or removing existing data due to their inherent structure where knowledge is stored within model weights. This inflexibility poses a problem for data privacy, especially with regulations like GDPR that empower users to request the deletion of their data. The proposed method tackles these issues by combining pre-trained image encoders, ResNet and Vision Transformer (ViT), with the k-NN algorithm.
The process involves:
- Supervised Feature Embedding: The pre-trained ResNet or ViT model extracts features from images in the support set to create embeddings. These embeddings, along with corresponding labels, are stored in an external database, Chroma.
- Classification of New Image: When a new image needs to be classified, the same pre-trained model extracts its features and generates an embedding.
- k-NN for Classification: The new image's embedding is compared to the stored embeddings in Chroma. The k-nearest neighbors, determined using a distance metric like cosine similarity, are identified.
- Classification: A majority vote on the labels of these k-nearest neighbors determines the classification of the new image.
This approach offers several benefits:
- Continual Learning: New data (classes or samples) can be seamlessly added to the database without retraining the entire model. This facilitates continual learning and mitigates catastrophic forgetting, a common issue in traditional models.
- Data Privacy: Data can be easily removed from the database to comply with user requests, without requiring computationally expensive model retraining.
- Explainability: The decision-making process is transparent. The k-nearest neighbors and their similarity score to the query image can be visualized to explain the classification.
- Cost-Effective: The approach leverages pre-trained models, eliminating the need for resource-intensive training from scratch.
The thesis evaluated the performance of this k-NN approach across a range of datasets, including CIFAR-10, CIFAR-100, STL-10, Pneumonia, and Melanoma. Experiments explored the impact of different hyperparameters, including the value of 'k' in the k-NN algorithm. Additionally, different dimensionality reduction techniques were assessed to visualize and explain the decision process of the proposed approach. The research showcases the efficacy of the k-NN approach. For instance, the approach achieves accuracies of 98.5% on CIFAR-10, 88.3% on CIFAR-100, and 99.5% on STL-10, demonstrating strong performance on natural image datasets. It also performs well on medical image datasets, achieving 89.9% accuracy on Pneumonia and 69.8% on Melanoma. Notably, these results on medical datasets are comparable to, and in some cases even exceed, the performance of fully supervised state-of-the-art models, highlighting the transfer learning capabilities of the approach. The thesis aims to demonstrate that this k-NN-based approach is a viable and advantageous alternative to traditional deep learning models for image classification. It presents a compelling case for a more adaptable, privacy-aware, explainable, and cost-effective solution.
Link to thesis(18.9 MB)
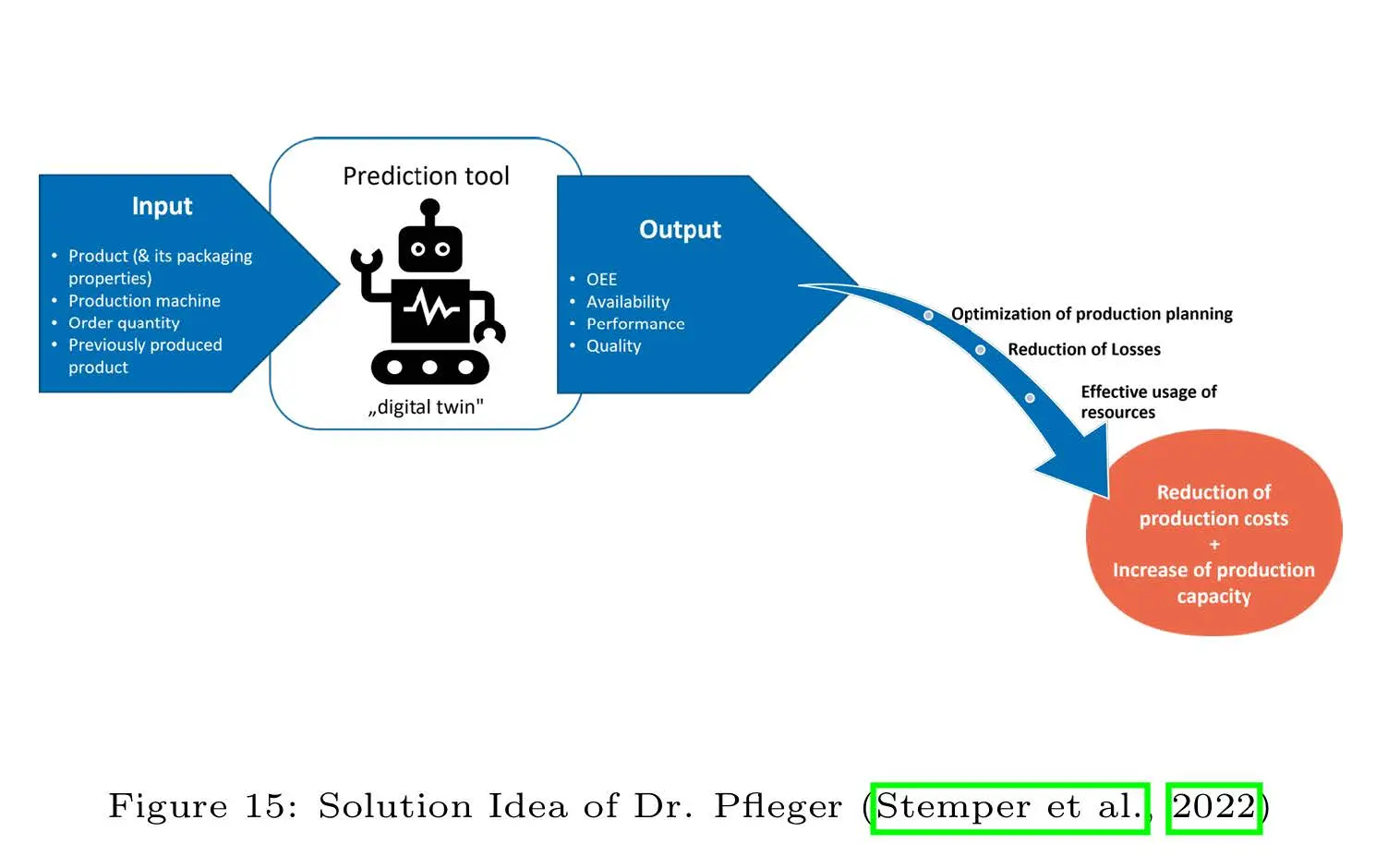
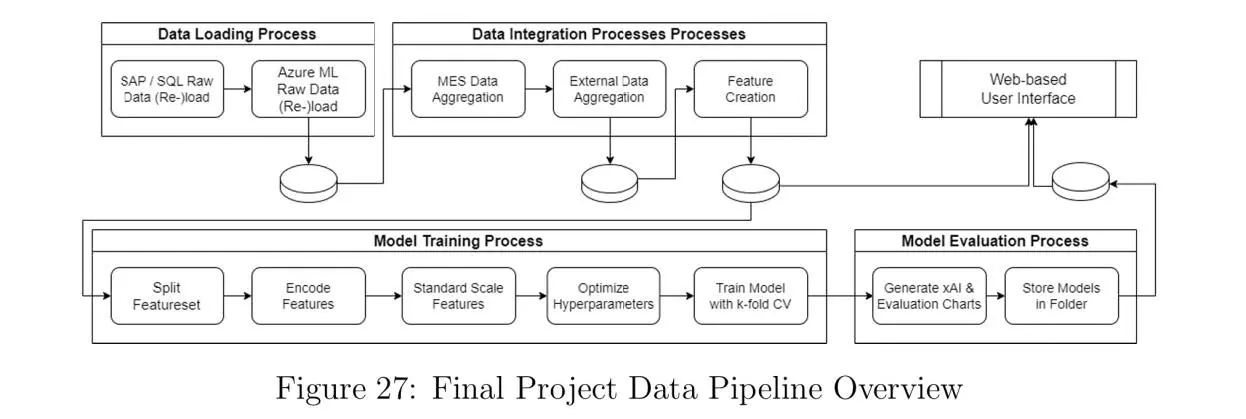
?Evaluation and feasibility of selected data-driven Machine Learning approaches for Production Planning to enhance Order Sequencing and to improve OEE in Manufacturing“ - Nicolai Frosch
Autor: Nicolai Frosch, betreut von Christian Ledig
The thesis investigates the use of data-driven machine learning (ML) techniques to improve production planning and enhance Overall Equipment Effectiveness (OEE) in the pharmaceutical manufacturing industry, conducted in collaboration with Dr. Pfleger Arzneimittel GmbH. The study investigates the OEE, which measures key challenges in production scheduling, including machine downtime, suboptimal performance, and quality inefficiencies.
Through a structured methodology rooted in action research and Design Science Research (DSR), the project incorporates data integration, feature engineering, model training, and hyperparameter optimization to predict OEE and other Key Performance Indicators (KPIs). Ten different ML-algorithms were evaluated, with ensemble methods emerging as top performers in predicting the OEE. To ensure stakeholder trust and transparency, the models were investigated with SHAP values. While implementing the ML-algorithms this thesis phased classical challenge of practical projects, like limited data availability, bad data quality and changing project goals during the implementation period.
The research outcomes include a functional prototype of a web-based user interface that integrates trained ML models to support human planners in generating optimized production schedules. The interface enables planners to simulate production scenarios, visualize scheduling proposals, and make informed decisions to reduce downtime and operational losses. Although fully autonomous scheduling was beyond the project's scope, the thesis demonstrates the potential of ML-driven decision-support systems in achieving incremental efficiency gains and minimizing production losses.
This work underscores the feasibility of using machine learning to predict KPIs and improve production planning, showing in a practical setting how ML can be used in smart manufacturing. It provides a foundation for future developments toward autonomous scheduling and increased operational excellence in the manufacturing domain.
Link to thesis(9.9 MB)

?AI-assisted wood knots detection from historic timber structure imaging“ - Junquan Pan
Autor: Junquan Pan, betreut von Christian Ledig
This thesis presents an AI-based system for the automated detection of wood knots in historic timber structures, designed to support heritage conservation efforts. Traditional manual methods for assessing the condition of timber structures are often inefficient, error-prone and unsuitable for challenging environments. By integrating advanced machine learning and deep learning technologies, such as Detectron2 and YOLOv8, this work introduces a robust and systematic workflow to improve the accuracy and efficiency of timber defect analysis.
The research involves two main stages: segmentation to identify wood surfaces, and detection to locate and analyse wood knots. High-resolution datasets were meticulously collected from heritage sites, including the Dominican Church in Bamberg, as well as timber workshops, to ensure diverse and high-quality training data. These datasets were used to train and validate the proposed models, overcoming challenges such as varying lighting conditions, irregular wood textures and knot complexity.
The system not only facilitates accurate assessment of wood condition, but also contributes to the conservation of historic resources by minimising unnecessary material replacement. The ultimate goal is to provide conservators with a mobile application that integrates these AI-driven tools, enabling efficient and detailed in-situ analysis of wooden structures. This work highlights the transformative potential of AI in heritage conservation, bridging the gap between traditional techniques and modern computational methods.
Link to thesis(14.3 MB)
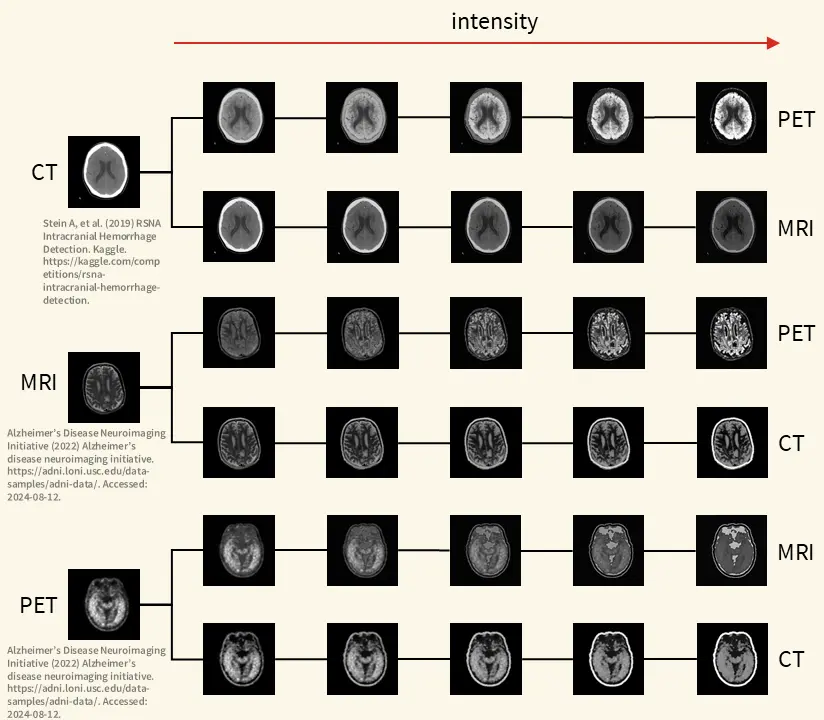
?Towards Multimodal Deep Learning for Medical Image Analysis: Developing a Cross-Modality Data Augmentation Technique by Interpolating Modality-Specific Characteristics in Medical Images" - Julius Stutz
Autor: Julius Stutz, betreut von Sebastian D?rrich
This thesis explores the challenge of data scarcity in medical imaging for deep learning applications and presents the Cross-Modality Data Augmentation (CMDA) as a new approach. Medical imaging data is limited due to privacy concerns, ethical restrictions, and technical constraints, which makes model development substantially harder in this domain. CMDA addresses these challenges by translating images between modalities (medical imaging techniques) such as PET, MRI, and CT to enhance dataset diversity and improve model robustness.
CMDA consists of four augmentations tailored to modality-specific characteristics: color, artifacts, spatial resolution, and noise. It allows to adjust its settings appropriately for each use-case and integrates seamlessly into existing data augmentation pipelines. The method aims to synthesize new training samples that visually align with the target modality, potentially improving generalization in neural networks.
The approach was evaluated through quantitative experiments, comparing classification performance of models trained with CMDA and other augmentations. Results showed marginal improvements in some cases but noticeable performance drops in others. Qualitative experiments, however, demonstrated CMDA’s success in aligning images to target modalities, with two experiments showing an average alignment improvement of 23.5%.
Despite limitations in model generalization and robustness, CMDA demonstrates its potential in addressing cross-modality challenges, offering a foundation for future research in medical data augmentation and image translation.
Link to thesis(18.7 MB)

?Generative Data Augmentation in the Embedding Space of Vision Foundation Models to Address Long-Tailed Learning and Privacy Constraints” - David Elias Tafler
Autor: David Elias Tafler, betreut von Francesco Di Salvo
This thesis explores the potential of generative data augmentation in the embedding space of vision foundation models, aiming to address the challenges of long-tailed learning and privacy constraints. Our work leverages Conditional Variational Autoencoders (CVAEs) to enrich the representation space for underrepresented classes in highly imbalanced datasets and to enhance data privacy without compromising utility. We develop and assess methods that generate synthetic data embeddings conditioned on class labels, which both mimic the distribution of original data for privacy purposes and augment data for tail classes to balance datasets. Our methodology shows that embedding-based augmentation can effectively improve classification accuracy in long-tailed scenarios by increasing the diversity and volume of minor class samples. Additionally, we demonstrate that our approach can generate data that maintains privacy through effective anonymization of embeddings. The outcomes suggest that generative augmentation in embedding spaces of foundation models offers a promising avenue for enhancing model robustness and data security in practical applications. The findings have significant implications for deploying machine learning models in sensitive domains, where data imbalance and privacy are critical concerns.
Link to thesis(8.8 MB)

??Exploring and Evaluating Deep Hashing Methods within Vision Foundation Model Feature Spaces for Similarity Search and Privacy Preservation’’ - Peiyao Mao
Autor: Peiyao Mao, betreut von Francesco Di Salvo
This thesis investigates the efficacy of deep hashing methods applied to image embeddings derived from state-of-the-art Vision Transformer (ViT) models, focusing on both the semantic preservation be tween original image embeddings and hashed image embeddings and the strengthening of data privacy. The contribution of the experiment involves the transformation of image embeddings to hashed image embeddings using various deep supervised hashing methods, making sure the semantic similarities are preserved, and data privacy is enhanced. We innovatively apply Triplet Center Loss (TCL) in the domain of deep hashing, aiming to achieve both high performance and computational efficiency. By comparing various deep supervised hashing methods, including pairwise and triplet methods, the experiment try to understand and evaluate how different approaches perform under the same conditions. It provides insights into which methods are most effective in retaining important data characteristics after hashing. A key aspect of this research is the emphasis on privacy preservation. By converting raw image data into hashed forms, this work explores how advanced hashing techniques can obscure original data features, thereby enhancing privacy without substantially compromising the utility for tasks such as medical image retrieval. This dual focus addresses the critical challenge of using sensitive image data in environments where privacy concerns are important.
Link to thesis(2.7 MB)

?Unveiling CNN Layer Contributions: Application of Feature Visualization in Medical Image Classification Tasks” - Jonida Mukaj
Autor: Jonida Mukaj, betreut von Ines Rieger
This thesis explores the application of feature visualisations on medical datasets, specifically for skin cancer imaging, using pre-trained convolutional neural networks like AlexNet, VGG16, and ResNet50 to enhance model interpretability, and fine-tuning those models to the ISIC benchmark dataset. Comparative analysis of ISIC 2019 and 2020 datasets shows varying model strengths, with VGG16 leading in accuracy and ResNet50 generalizability. Feature visualizations reveal diagnostic patterns in skin cancer, aiding in understanding network decision-making, yet pose challenges in medical interpretation. The study underscores the importance of deep learning in medical imaging and suggests combining feature visualizations with other interpretability techniques for future advancements.
Link to thesis(17.2 MB)

"CNN-based Classification of I-123 ioflupane dopamine transporter SPECT brain images to support the diagnosis of Parkinson’s disease with Decision Confidence Estimation"- Aleksej Kucerenko
Autor: Aleksej Kucerenko, betreut von Prof. Dr. Christian Ledig and Dr. Ralph Buchert
Parkinson's disease (PD) is a prevalent neurodegenerative condition posing significant challenges to individuals and societies alike.
It is anticipated to become a growing burden on healthcare systems as populations age.
The differentiation between PD and secondary parkinsonian syndromes (PS) is crucial for effective treatment, yet it remains challenging,
particularly in cases of clinically uncertain parkinsonian syndromes (CUPS).
Dopamine transporter single-photon emission computed tomography (DAT-SPECT) is a widely used diagnostic tool for PD,
offering high accuracy but also presenting interpretational challenges, especially in borderline cases.
This study aims to develop reliable automated classification methods for DAT-SPECT images, particularly targeting inconclusive cases,
which may be misclassified by conventional approaches.
Convolutional neural networks (CNNs) are investigated as promising tools for this task.
The study proposes a novel performance metric, the area under balanced accuracy (AUC-bACC) over the percentage of inconclusive cases,
to compare the performance of CNN-based methods with benchmark approaches (SBR and Random Forest).
A key focus is the training label selection strategy, comparing majority vote training (MVT) with random label training (RLT),
which aims to expose the model to the uncertainty inherent in borderline cases.
The study evaluates the methods on internal and external testing datasets to assess generalizability and robustness.
The research was conducted in collaboration with the University Medical Center Hamburg-Eppendorf (UKE).
The dataset utilized for model training originated from clinical routine at the Department of Nuclear Medicine, UKE.
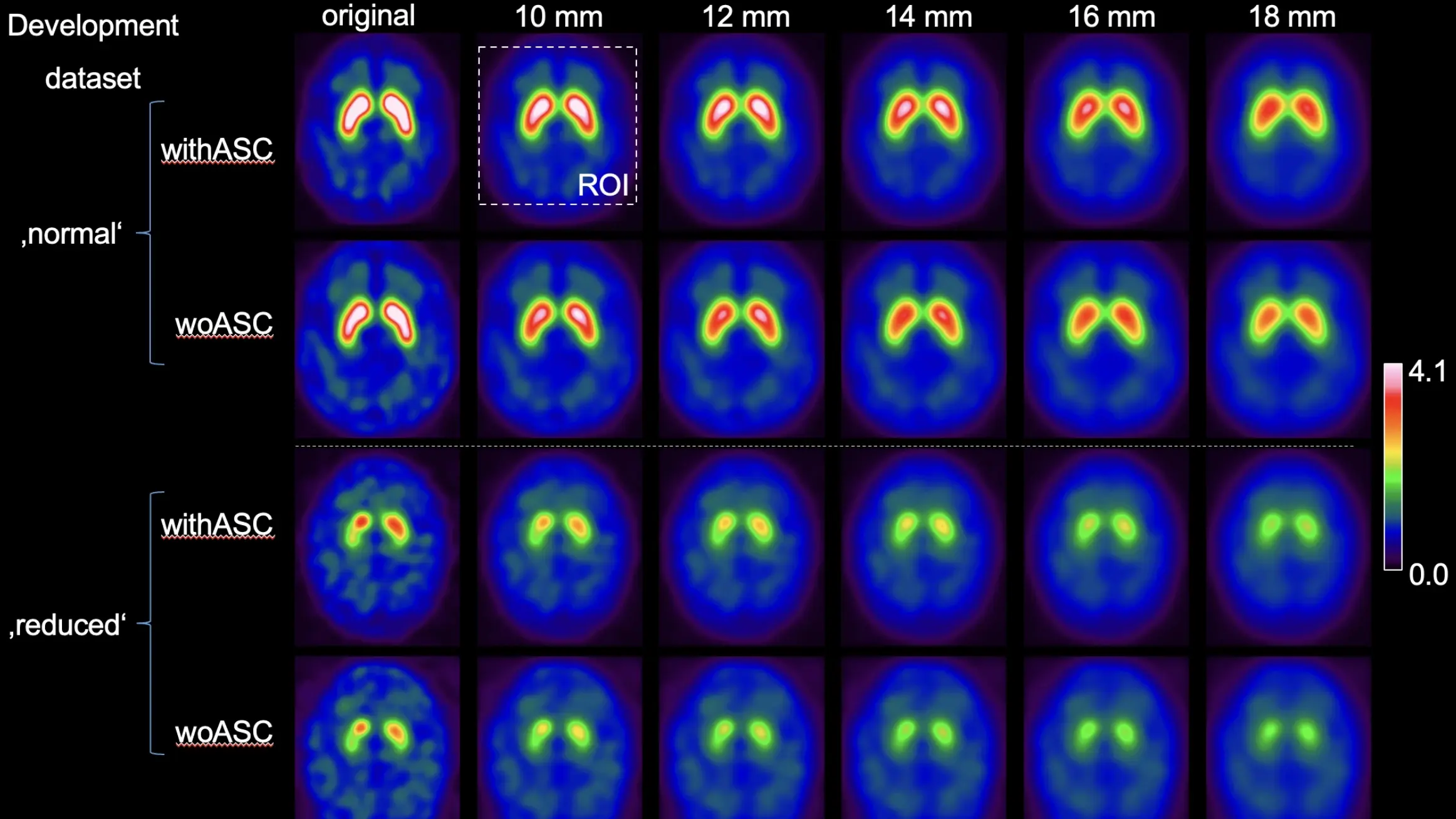
The attached figure showcases augmented versions for two sample cases from the dataset:
a healthy control case ('normal') and a Parkinson's disease case ('reduced') with reduced availability of DAT in the striatum.
The study addresses the need for reliable and automated classification of DAT-SPECT images,
providing insights into improving diagnostic accuracy,
reducing the burden of misclassifications and minimizing the manual inspection effort.
Link to thesis(12.5 MB)
Benchmarking selected State-of-the-Art Baseline Neural Networks for 2D Biomedical Image Classification, Inspired by the MedMNIST v2 Framework"- Julius Brockmann

Autor: Julius Brockmann, betreut von Sebastian D?rrich
This thesis examines the benchmarking of state-of-the-art baseline neural networks in the field of 2D biomedical image classification. Focusing on the effectiveness of deep learning models on high-quality medical databases, the study employs pre-trained baseline networks to establish benchmarks. The research investigates four convolutional neural
networks and one transformer-based architecture, exploring how changes in image resolution affect performance. The findings highlight the advanced capabilities of newer convolutional networks and demonstrate the effectiveness of transformer architectures for handling large datasets. Common misclassifications and their causes are also briefly analyzed, offering insights into potential areas for improvement in future studies.
Link to thesis(8.4 MB)
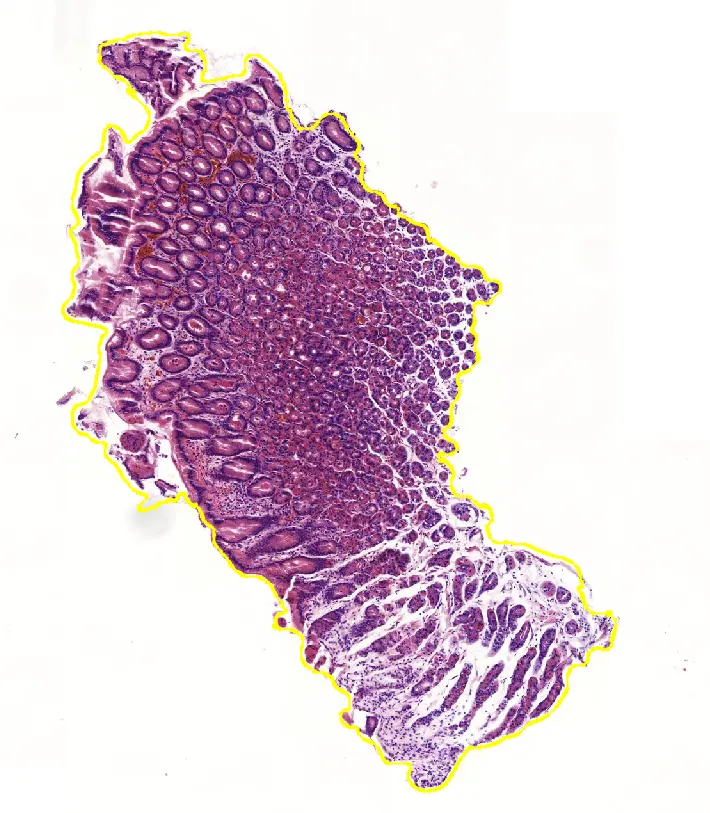
"Development of a dataset and AI-based proof-of-concept algorithm for the classification of digitized whole slide images of gastric tissue"- Tom Hempel
Autor: Tom Hempel, betreut von Prof. Dr. Christian Ledig
The thesis focuses on the development of a dataset and AI algorithms for classifying digitized whole slide images (WSIs) of gastric tissue. It details the creation and meticulous annotation of the dataset, which is crucial for effectively training the AI. The process involved gathering, anonymizing, and annotating a vast array of WSIs, aimed at building robust AI models that can accurately classify different regions of the stomach and identify inflammatory conditions.
Two AI models were developed, one for assessing gastric regions and another for inflammation detection, achieving high accuracy in areas like the antrum and corpus but facing challenges with intermediate regions due to dataset limitations and the specificity of training samples.
The challenges encountered during the dataset creation, such as data collection and the necessity for detailed annotation to ensure data integrity and privacy, highlight the complexity of this research.
The dataset and initial models serve as a foundation for further research by Philipp Andreas H?fling in his master thesis, aiming to refine these AI algorithms and enhance their utility in medical diagnostics.
Link to thesis(5.1 MB)

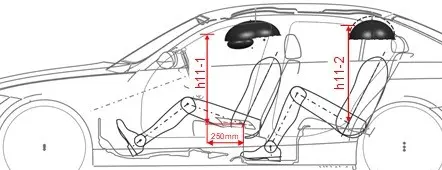
"Component ldentification for Geometrie Measurements in the Vehicle Development Process Using Machine Learning" - Tobias Koch
Autor: Tobias Koch, betreut von Prof. Dr. Christian Ledig
Geometric measurements are frequently performed along the virtual vehicle development chain to monitor and confirm the fulfillment of dimensional requirements for purposes like safety and comfort. The current manual measuring process lacks in comparability and quality aspects and involves high time and cost expenditure due to the repetition across different departments, engineers, and vehicle projects.
Thereby motivated, this thesis presents an automated approach to component identification, leveraging the power of Machine Learning (ML) in combination with rule-based filters. It streamlines the geometric measurement process by classifying vehicle components as relevant or not and assigning uniformly coded designations. To determine the most effective approach, the study compares various ML models regarding performance and training complexity, including Light Gradient-Boosting Machines (LightGBMs), eXtreme Gradient Boosting (XGBoost), Categorical Boosting (CatBoost), and Feedforward Neural Networks (FNNs).
The results indicate that the integration of ML models can substainally improve the geometric measurement process in the virtual vehicle development process. Especially LightGBM and CatBoost proved to be the most capable models for this tasks and offer promising progress in the virtual development of vehicles.
Link to the thesis(3.6 MB)
Weitere abgeschlossene Abschlussarbeiten
- "Reproduction of Selected State-of-the-Art Methods for Anomaly Detection in Time Series Using Generative Adversarial Networks" - Anastasia Sinitsyna, betreut von Ines Rieger
- “Feasibility of Deep Learning-based Methods for the Classification of Real and Simulated Electrocardiogram Signals” - Markus Brücklmayr, betreut von Christian Ledig
- “Designing a Benchmark and Leaderboard System for Assessing the Generalizability of Deep Learning Approaches for Medical Image Classification using the MedMNIST+ Dataset Collection” - Marius Ludwig Bachmeier, betreut von Sebastian D?rrich [code] [thesis(4.9 MB)]
- “Exploring the Generalization Potential and Distortion Robustness of Foundation Models in Medical Image Classification by Introducing a New Benchmark for the Multidimensional MedMNIST+ Dataset Collection” - Alexander Haas, betreut von Sebastian D?rrich [thesis(23.6 MB)]
- “Deep Learning based Legibility Evaluation using Images of Children's Handwriting" - Aaron-Lukas Pieger, Zusammenarbeit mit Stabilo, betreut von Christian Ledig [thesis(24.5 MB)]
- “Deep Learning based Evaluation of Handwriting Legibility using a Sensor Enhanced Ballpoint Pen” - Erik-Jonathan Schmidt, Zusammenarbeit mit Stabilo, betreut von Christian Ledig [thesis(13.0 MB)]
- “Exploring Data Efficiency of Foundation Models for Fine-Grained Image Classification of Lepidopteran Species” - Leopold Heinrich Gierz, betreut von Jonas Alle